이번 포스팅은 Object Detection을 위한 Neural Network에서 자주 보는 Image Pyramid와,
이와 연관한 Object Detection Network의 Feature 추출 단계에 대한 것이다.
Image Pyramid란
Input Image의 Size를 단계별로 변화시키면서 쌓은 형태를 말한다.

위의 사진은 Gaussian Pyramid로
한 단 올라갈 때 마다 해상도가 절반으로 줄어드는 것을 볼 수 있다.
해상도가 절반으로 줄어든다는 것은 즉 픽셀 수의 감소를 뜻하는데,
보통 짝수 픽셀을 모두 지우고 홀수 픽셀만 남겨두는 식으로 해상도를 저하시킨다고 한다.
이렇게 만들어진 Image Pyramid에서
각 단계 (level)마다 고정된 크기의 윈도우를 이동시키며 Object를 detect한다.
이러한 Image Pyramid는 Object Detection Network에서 흔히 볼 수 있는데,
그렇다면 이것이 왜 필요할까?
Object Detection 뿐만 아니라 모든 딥러닝 네트워크를 통한 학습에서 가장 중요한 과제는 "일반화"이다.
Training Set에만 잘 작동하는 것이 아니고, 랜덤한 Input을 넣어주어도 잘 작동해야하는 것이다.
이와 관련해서, 사람이 어떤 사진을 인식할 때에는 크기가 그리 중요하지 않다.
작은 꽃과 큰 꽃을 보여줘도 모양만 같다면 사람은 쉽게 두 꽃의 종류가 같은 걸 인식할 수 있다.
하지만 딥러닝은 Size만 다른 같은 사진이어도, 전혀 인식하지 못할 수 있다.
따라서 딥러닝은 모델의 Size-Invarience가 중요하다.
이 Size- Invarience를 위해 사용되는 개념이 바로 Image Pyramid이다.
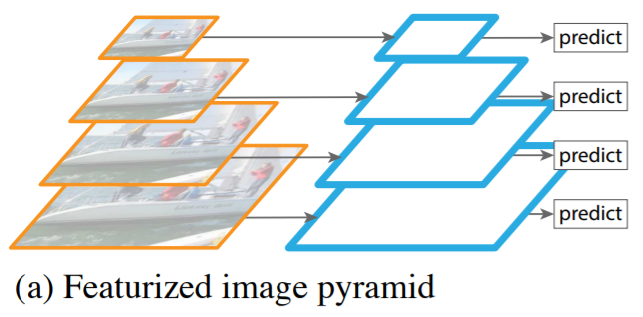
위의 Featurized Image Pyramid는 Image Pyramid를 사용한 특징추출 구조이다.
각 단계 (level)에서 모두 개별적인 Feature를 추출하여 Object Detection을 수행하는 것이다.
하지만, Scale만 다를 뿐 모두 같은 영상인데 개별적으로 Feature를 추출하기 때문에 비효율적이다.
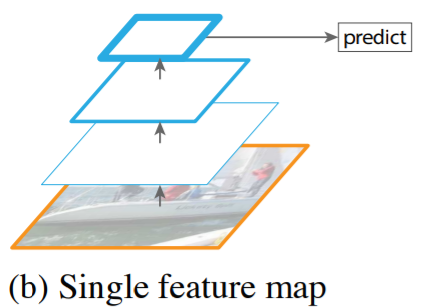
이제부터는 Image Pyramid가 아니고 Feature Pyramid라 할 수 있겠다.
Single feature map은 각 단계에서 모두 Feature를 추출하지 않고,
Feature를 추출하되 이를 Convolutional Layer를 통해 압축한다.
따라서 하나의 Input 사진에 대해 여러 번 Feautre를 추출하던 (a) 방식과는 달리
하나의 Input 사진에 대해 네트워크의 끝에서 하나의 Output을 내놓는다.
다만 (a) 보다 성능이 떨어진다.
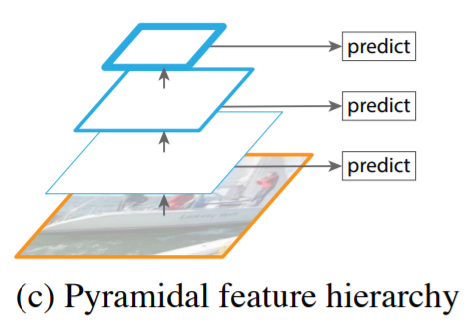
Pyramidal feature hierachy는 유명한 1-stage model인 SSD에서 사용하는 특징추출 방식이다.
(b)와 마찬가지로 단일 scale의 영상을 이용하지만
(b)와 다르게 각 level에서 개별적으로 Feature를 추출한다.
즉, (b)에서는 상위 feature을 가져와 현 level에서의 추출된 feature를 함께 압축하여 사용한다면
여기는 상위에서 추출된 feature와 현 level에서 추출된 feature는 독립적인 것이다.

드디어 나왔다 FPN!
위로 올라가면서 특징을 추출하고, 다시 내려오면서 Object Detection 하는 Top-Down 방식.
각 level에서 feature가 추출된 결과들을 연결해서 Detection한다.
즉, semantic이 강한 low resolution과 semantic이 약한 high resolution을 연결해서 사용하는 것.
따라서 모든 scale에서 semantic을 강화하겠다는 전략.
FPN은 Bottom-Up 과 Top-Down 단계로 나뉜다.
Bottom- Up:
쉽게 말해서 해상도가 감소하는 위로 올라가는 부분이 forward 단계이다.
동일한 output map 크기인 레이어들을 하나의 Stage로 취급하고 output map 크기가 달라지면 다음 Stage로 넘어간다고 보면 된다.
FPN에서는 하나의 Stage마다 하나의 Pyramid level (위의 그림에서의 네모) 가 정의된다.
Forward 단계에서는 매 level (네모) 마다 semantic을 압축하는 역할을 한다.
또, 각 Stage의 마지막 레이어를 Skip-Connection에 사용한다.
각 Stage의 마지막 레이어에 가장 강한 특징이 있다는 것인데,
이를 skip-connection함으로써 Pyramid의 feature를 더욱 강화한다.
Top- Down:
아래로 내려오는 네트워크가 해상도가 다시 증가하는 UpSampling 구간이다.
이 구간에서는 semantics 를 가지고 있는 Feature map들을 다시 2배로 UpSampling 하여, 기존의 손실시켰던 해상도를 복구하는 작업을 한다.
여기서 앞서 Bottom-up의 Skip-Connection Layer을 다시 이용해
Bottom-up Layer 와 Top-down Layer (물론 둘은 같은 사이즈) 를 합쳐서 손실된 지역적 정보를 보충한다.
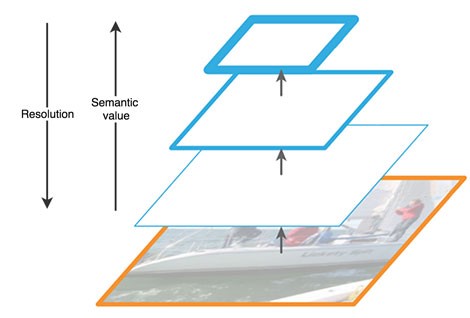
위의 그림은 FPN 에서 Bottom-Up과 Top-Down의 상호작용을 잘 나타내준다.
위로 올라갈수록, 즉 High pyramid level일수록 Semantic에 강하다. 반면, Spatially 해상도가 약하다.
이렇게 semantic rich한 layer를
Top-Down 과정에서 UpSampling 해 High Resolution으로 만드는 과정이 핵심이라고 볼 수 있다.
이렇게 DownSampling, UpSampling 을 통해 재건된 레이어들은 이제 Sementic Strong해지고 High Resolution이 되었다. 하지만 UpSampling을 통한 Resolution 향상은 절대 원본을 따라갈 수 없다.
즉, 정확하지 않다는 소리다.
이것이 FPN 이 lateral connection을 도입하는 이유이다.
재건된 layer들과, 같은 사이즈의 feature map을 lateral connection (skip connection) 을 통해 합치는 것이다.
이렇게 Top down에서 Bottom-Up layer와 합치는 작업을 통해 정확하지 않았던 지역 정보를 보충한다.
이 때 채널 수를 줄이기 위해 1 x 1 convolutional filter를 적용한다.
(아래 그림 참조)

'Computer Vision > Deep Learning' 카테고리의 다른 글
| no module named 'tensorflow' error 해결 (0) | 2020.09.27 |
|---|---|
| Object Detection의 결과 성능 평가지표들 (0) | 2020.08.07 |
| Gaussian Mixture Model - GMM (0) | 2020.07.09 |
| SNIPER: Efficient Multi-Scale Training (0) | 2020.02.20 |


